 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerson Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025
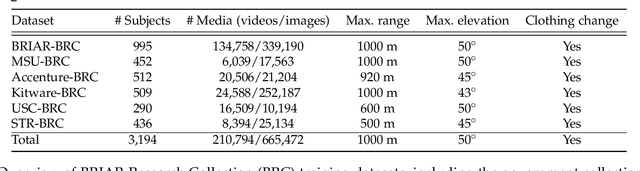

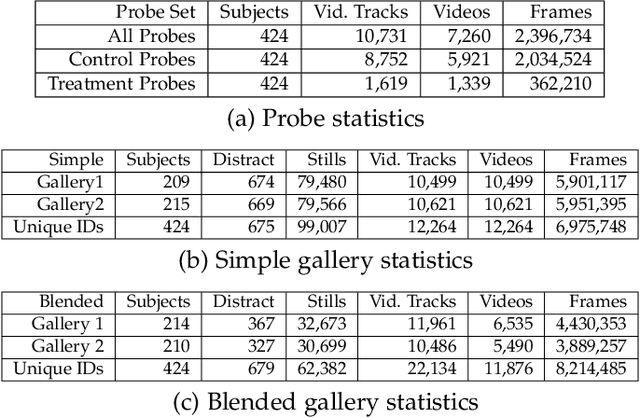
We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
DaliID: Distortion-Adaptive Learned Invariance for Identification Models
Feb 11, 2023



In unconstrained scenarios, face recognition and person re-identification are subject to distortions such as motion blur, atmospheric turbulence, or upsampling artifacts. To improve robustness in these scenarios, we propose a methodology called Distortion-Adaptive Learned Invariance for Identification (DaliID) models. We contend that distortion augmentations, which degrade image quality, can be successfully leveraged to a greater degree than has been shown in the literature. Aided by an adaptive weighting schedule, a novel distortion augmentation is applied at severe levels during training. This training strategy increases feature-level invariance to distortions and decreases domain shift to unconstrained scenarios. At inference, we use a magnitude-weighted fusion of features from parallel models to retain robustness across the range of images. DaliID models achieve state-of-the-art (SOTA) for both face recognition and person re-identification on seven benchmark datasets, including IJB-S, TinyFace, DeepChange, and MSMT17. Additionally, we provide recaptured evaluation data at a distance of 750+ meters and further validate on real long-distance face imagery.
Towards Multimodal Vision-Language Models Generating Non-Generic Text
Jul 09, 2022
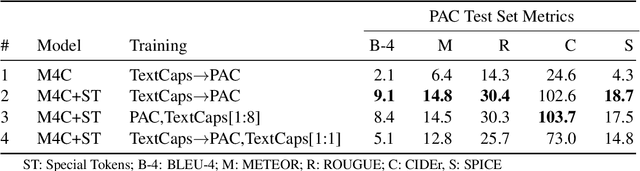
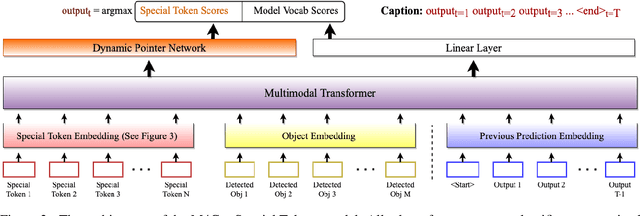

Vision-language models can assess visual context in an image and generate descriptive text. While the generated text may be accurate and syntactically correct, it is often overly general. To address this, recent work has used optical character recognition to supplement visual information with text extracted from an image. In this work, we contend that vision-language models can benefit from additional information that can be extracted from an image, but are not used by current models. We modify previous multimodal frameworks to accept relevant information from any number of auxiliary classifiers. In particular, we focus on person names as an additional set of tokens and create a novel image-caption dataset to facilitate captioning with person names. The dataset, Politicians and Athletes in Captions (PAC), consists of captioned images of well-known people in context. By fine-tuning pretrained models with this dataset, we demonstrate a model that can naturally integrate facial recognition tokens into generated text by training on limited data. For the PAC dataset, we provide a discussion on collection and baseline benchmark scores.